Working with data
Modeling data
In this section we’ll learn how to model data using Instant's schema. By the end of this document you’ll know how to:
- Create namespaces and attributes
- Add indexes and unique constraints
- Model relationships
- Lock down your schema for production
We’ll build a micro-blog to illustrate; we'll have authors, posts, comments, and tags.
#Schema as Code
With Instant you can define your schema and your permissions in code. If you haven't already, use the CLI to generate an instant.schema.ts, and a instant.perms.ts file:
npx instant-cli@latest init
The CLI will guide you through picking an Instant app and generate these files for you.
#instant.schema.ts
Now we can define the data model for our blog!
Open instant.schema.ts, and paste the following:
// instant.schema.tsimport { i } from '@instantdb/react';const _schema = i.schema({entities: {$users: i.entity({email: i.string().unique().indexed(),}),profiles: i.entity({nickname: i.string(),createdAt: i.date(),}),posts: i.entity({title: i.string(),body: i.string(),createdAt: i.date(),}),comments: i.entity({body: i.string(),createdAt: i.date(),}),tags: i.entity({title: i.string(),}),},links: {postAuthor: {forward: { on: 'posts', has: 'one', label: 'author' },reverse: { on: 'profiles', has: 'many', label: 'authoredPosts' },},commentPost: {forward: { on: 'comments', has: 'one', label: 'post' },reverse: { on: 'posts', has: 'many', label: 'comments' },},commentAuthor: {forward: { on: 'comments', has: 'one', label: 'author' },reverse: { on: 'profiles', has: 'many', label: 'authoredComments' },},postsTags: {forward: { on: 'posts', has: 'many', label: 'tags' },reverse: { on: 'tags', has: 'many', label: 'posts' },},profileUser: {forward: { on: 'profiles', has: 'one', label: '$user' },reverse: { on: '$users', has: 'one', label: 'profile' },},},});// This helps TypeScript display better intellisensetype _AppSchema = typeof _schema;interface AppSchema extends _AppSchema {}const schema: AppSchema = _schema;export type { AppSchema };export default schema;
Let's unpack what we just wrote. There are three core building blocks to model data with Instant: Namespaces, Attributes, and Links.
#1) Namespaces
Namespaces are equivalent to "tables" in relational databases or "collections" in NoSQL. In our case, these are: $users, profiles, posts, comments, and tags.
They're all defined in the entities section:
// instant.schema.tsconst _schema = i.schema({entities: {posts: i.entity({// ...}),},});
#2) Attributes
Attributes are properties associated with namespaces. These are equivalent to a "column" in relational databases or a "field" in NoSQL. For the posts entity, we have the title, body, and createdAt attributes:
// instant.schema.tsconst _schema = i.schema({entities: {// ...posts: i.entity({title: i.string(),body: i.string(),createdAt: i.date(),}),},});
#Typing attributes
Attributes can be typed as i.string(), i.number(), i.boolean(), i.date(), i.json(), or i.any().
i.date() accepts dates as either a numeric timestamp (in milliseconds) or an ISO 8601 string. JSON.stringify(new Date()) will return an ISO 8601 string.
When you type posts.title as a string:
// instant.schema.tsconst _schema = i.schema({entities: {// ...posts: i.entity({title: i.string(),// ...}),},});
Instant will make sure that all title attributes are strings, and you'll get the proper typescript hints to boot!
#Required constraints
All attributes you define are considered required by default. This constraint is enforced on the backend: Instant guarantees that every entity of that type will have a value and reports errors if you attempt to add an entity without a required attribute.
const _schema = i.schema({entities: {posts: i.entity({title: i.string(), // <-- requiredpublished: i.date(), // <-- required}),},});db.transact(db.tx.posts[id()].update({title: 'abc', // <-- no published -- will throw}),);
You can mark an attribute as optional by calling .optional():
const _schema = i.schema({entities: {posts: i.entity({title: i.string(), // <-- requiredpublished: i.date().optional(), // <-- optional}),},});db.transact(db.tx.posts[id()].update({title: 'abc', // <-- no published -- still okay}),);
This will also reflect in types: query results containing posts will show title: string (non-nullable) and published: string | number | null (nullable).
You can set required on forward links, too:
postAuthor: {forward: { on: 'posts', has: 'one', label: 'author', required: true },reverse: { on: 'profiles', has: 'many', label: 'authoredPosts' },},
Finally, for legacy attributes that are treated as required on your front-end but you are not ready to enable back-end required checks yet, you can use .clientRequired(). That will produce TypeScript type without null but will not add back-end required check:
const _schema = i.schema({entities: {posts: i.entity({title: i.string().clientRequired(),published: i.date().optional(),}),},});
#Unique constraints
Sometimes you'll want to introduce a unique constraint. For example, say we wanted to add friendly URL's to posts. We could introduce a slug attribute:
// instant.schema.tsconst _schema = i.schema({entities: {// ...posts: i.entity({slug: i.string().unique(),// ...}),},});
Since we're going to use post slugs in URLs, we'll want to make sure that no two posts can have the same slug. If we mark slug as unique, Instant will guarantee this constraint for us.
Unique attributes will also speed up queries that filter by that attribute.
const query = {posts: {$: {where: {// Since `slug` is unique, this query is 🚀 fastslug: 'completing_sicp',},},},};
#Indexing attributes
You can also use index attributes to speed up querying. An additional benefit is that indexed attributes can be used with comparison operators for where queries like $gt, $lt, $gte, and $lte and can be used in order clauses.
Suppose we wanted to query for products less than $100 and order by price.
First we make sure that the price attribute is indexed:
// instant.schema.tsconst _schema = i.schema({entities: {// ...products: i.entity({price: i.number().indexed(), // 🔥,// ...}),},});
And now we can use $lt and order in our query:
const query = {products: {$: {where: {price: { $lt: 100 },},order: {price: 'desc',},},},};
Even if you're not using comparison operators or order clauses, indexing attributes can still speed up queries that filter by that attribute.
#3) Links
Links connect two namespaces together. When you define a link, you define it both in the 'forward', and the 'reverse' direction. For example:
postAuthor: {forward: { on: "posts", has: "one", label: "author" },reverse: { on: "profiles", has: "many", label: "authoredPosts" },}
This links posts and profiles together:
posts.authorlinks to oneprofilesentityprofiles.authoredPostslinks back to manypostsentities.
Since links are defined in both directions, you can query in both directions too:
// This queries all posts with their authorconst query1 = {posts: {author: {},},};// This queries profiles, with all of their authoredPosts!const query2 = {profiles: {authoredPosts: {},},};
Links can have one of four relationship types: many-to-many, many-to-one, one-to-many, and one-to-one
Our micro-blog example has the following relationship types:
- One-to-one between
profilesand$users - One-to-many between
postsandprofiles - One-to-many between
commentsandposts - One-to-many between
commentsandprofiles - Many-to-many between
postsandtags
#Cascade Delete
Links defined with has: "one" can set onDelete: "cascade". In this case, when the profile entity is deleted, all post entities will be deleted too:
postAuthor: {forward: { on: "posts", has: "one", label: "author", onDelete: "cascade" },reverse: { on: "profiles", has: "many", label: "authoredPosts" },}// this will delete profile and all linked postsdb.tx.profiles[user_id].delete();
Without onDelete: "cascade", deleting a profile would simply delete the links but not delete the underlying posts.
If you prefer to model links in other direction, you can do it, too:
postAuthor: {forward: { on: "profiles", has: "many", label: "authoredPosts" },reverse: { on: "posts", has: "one", label: "author", onDelete: "cascade" },}
#Publishing your schema
Now that you have your schema, you can use the CLI to push it to your app:
npx instant-cli@latest push schema
The CLI will look at your app in production, show you the new columns you'd create, and run the changes for you!
Checking for an Instant SDK...
Found @instantdb/react in your package.json.
Found NEXT_PUBLIC_INSTANT_APP_ID: *****
Planning schema...
The following changes will be applied to your production schema:
ADD ENTITY profiles.id
ADD ENTITY posts.id
ADD ENTITY comments.id
ADD ENTITY tags.id
ADD ATTR profiles.nickname :: unique=false, indexed=false
ADD ATTR profiles.createdAt :: unique=false, indexed=false
ADD ATTR posts.title :: unique=false, indexed=false
ADD ATTR posts.slug :: unique=true, indexed=false
ADD ATTR posts.body :: unique=false, indexed=false
ADD ATTR posts.createdAt :: unique=false, indexed=true
ADD ATTR comments.body :: unique=false, indexed=false
ADD ATTR comments.createdAt :: unique=false, indexed=false
ADD ATTR tags.title :: unique=false, indexed=false
ADD LINK posts.author <=> profiles.authoredPosts
ADD LINK comments.post <=> posts.comments
ADD LINK comments.author <=> profiles.authoredComments
ADD LINK posts.tags <=> tags.posts
ADD LINK profiles.$user <=> $users.profile
? OK to proceed? yes
Schema updated!
#Use schema for typesafety
You can also use your schema inside init:
import { init } from '@instantdb/react';import schema from '../instant.schema.ts';const db = init({appId: process.env.NEXT_PUBLIC_INSTANT_APP_ID!,schema,});
When you do this, all queries and transactions will come with typesafety out of the box.
If you haven't used the CLI to push your schema yet, no problem. Any time you write transact, we'll automatically create missing entities for you.
#Update or Delete attributes
You can always modify or delete attributes after creating them. You can't use the CLI to do this yet, but you can use the dashboard.
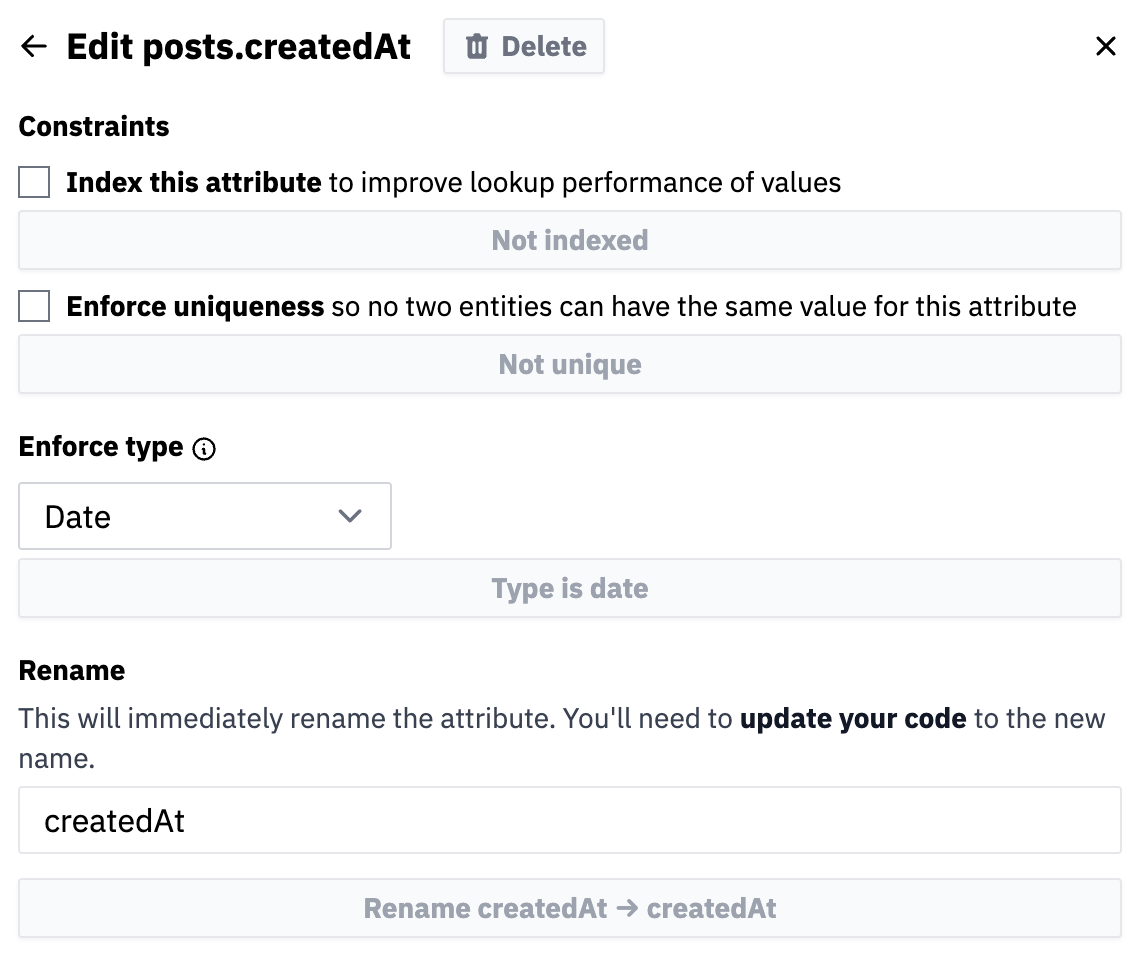
Say we wanted to rename posts.createdAt to posts.publishedAt:
- Go to your Dashboard
- Click "Explorer"
- Click "posts"
- Click "Edit Schema"
- Click
createdAt
You'll see a modal that you can use to rename the attribute, index it, or delete it:
#Secure your schema with permissions
In the earlier sections we mentioned that new entities and attributes can be created on the fly when you call transact. This can be useful for development, but you may not want this in production.
To prevent changes to your schema on the fly, simply add these permissions to your app.
// instant.perms.tsimport type { InstantRules } from '@instantdb/react';const rules = {attrs: {allow: {$default: 'false',},},} satisfies InstantRules;export default rules;
Once you push these permissions to production:
npx instant-cli@latest push perms
Checking for an Instant SDK...
Found @instantdb/react in your package.json.
Found NEXT_PUBLIC_INSTANT_APP_ID: *****
Planning perms...
The following changes will be applied to your perms:
-null
+{
+ attrs: {
+ allow: {
+ $default: "false"
+ }
+ }
+}
OK to proceed? yes
Permissions updated!
You'll still be able to make changes in the explorer or with the CLI, but client-side transactions that try to modify your schema will fail. This means your schema is safe from unwanted changes!
If you've made it this far, congratulations! You should now be able to fully customize and lock down your data model. Huzzah!